Comparación del motor de búsqueda de texto completo-Lucene, Sphinx, Postgresql, MySQL?
Estoy construyendo un sitio de Django y estoy buscando un motor de búsqueda.
Algunos candidatos:
Lucene/Lucene con Brújula/Solr
Esfinge
-
Postgresql built-in full text search
-
MySQL built-in full text search
Criterios de selección:
- relevancia y clasificación de los resultados
- velocidad de búsqueda e indexación
- facilidad de uso y facilidad de integración con Django
- recurso requisitos-el sitio estará alojado en un VPS , por lo que idealmente el motor de búsqueda no requeriría mucha RAM y CPU
- escalabilidad
- características adicionales como " ¿te referías?", búsquedas relacionadas, etc
Cualquiera que haya tenido experiencia con los motores de búsqueda anteriores, u otros motores que no están en la lista would Me encantaría escuchar sus opiniones.
EDITAR: En cuanto a las necesidades de indexación, como los usuarios siguen ingresando datos en el sitio, esos datos tendrían que ser indexados continuamente. No tiene que ser en tiempo real, pero idealmente los nuevos datos se mostrarían en el índice con no más de 15 - 30 minutos de retraso
8 answers
Es bueno ver a alguien hablando de Lucene, porque no tengo idea de eso.
Sphinx, por otro lado, lo sé bastante bien, así que veamos si puedo ser de alguna ayuda.
- La clasificación de relevancia de resultados es la predeterminada. Puede configurar su propia clasificación si lo desea, y dar a los campos específicos ponderaciones más altas.
- La velocidad de indexación es súper rápida, porque habla directamente con la base de datos. Cualquier lentitud vendrá de consultas SQL complejas y claves foráneas no indexadas y otros problemas. Nunca he notado ninguna lentitud en la búsqueda tampoco.
- Soy un tipo de Rails, así que no tengo idea de lo fácil que es implementar con Django. Sin embargo, hay una API de Python que viene con la fuente Sphinx.
- El servicio de búsqueda daemon (searchd) es bastante bajo en el uso de memoria - y puede establecer límites en la cantidad de memoria el proceso de indexador utiliza también.
- La escalabilidad es donde mi conocimiento es más incompleto, pero es bastante fácil copiar archivos de índice a múltiples máquinas y ejecutar varios demonios searchd. Sin embargo, la impresión general que obtengo de otros es que es bastante bueno bajo carga alta, por lo que escalarlo a través de varias máquinas no es algo que deba tratarse.
- No hay soporte para 'did-you-mean', etc., aunque esto se puede hacer con otras herramientas con bastante facilidad. Sphinx hace stem palabras aunque usando diccionarios, por lo que 'driving' y 'drive' (por ejemplo) se considerarían lo mismo en las búsquedas.
- La esfinge no sin embargo, permite actualizaciones parciales del índice para los datos de campo. El enfoque común para esto es mantener un índice delta con todos los cambios recientes, y volver a indexarlo después de cada cambio (y esos nuevos resultados aparecen dentro de un segundo o dos). Debido a la pequeña cantidad de datos, esto puede tomar una cuestión de segundos. Sin embargo, tendrá que volver a indexar el conjunto de datos principal regularmente (aunque la regularidad depende de la volatilidad de sus datos, todos los días? cada hora?). Las rápidas velocidades de indexación mantienen todo esto bastante indoloro.
No tengo idea de lo aplicable a su situación, pero Evan Weaver comparó algunas de las opciones de búsqueda comunes de Rails (Sphinx, Ferret (un puerto de Lucene para Ruby) y Solr), ejecutando algunos puntos de referencia. Podría ser útil, supongo.
No he profundizado en la búsqueda de texto completo de MySQL, pero sé que no compite en cuanto a velocidad ni características con Sphinx, Lucene o Solr.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/ajaxhispano.com/template/agent.layouts/content.php on line 61
2009-04-10 15:08:56
No conozco Sphinx, pero en cuanto a Lucene vs una base de datos de búsqueda de texto completo, creo que el rendimiento de Lucene es inigualable. Debería ser capaz de hacer casi cualquier búsqueda en menos de 10 ms, sin importar cuántos registros tenga que buscar, siempre que haya configurado correctamente su índice de Lucene.
Aquí viene el mayor obstáculo sin embargo: personalmente, creo que integrar Lucene en su proyecto no es fácil. Claro, no es demasiado difícil configurarlo para que pueda hacer algo básico busca, pero si quieres sacarle el máximo partido, con un rendimiento óptimo, entonces definitivamente necesitas un buen libro sobre Lucene.
En cuanto a los requisitos de CPU y RAM, realizar una búsqueda en Lucene no le asigna demasiada tarea a su CPU, aunque indexar sus datos sí lo es, aunque no lo haga con demasiada frecuencia (tal vez una o dos veces al día), por lo que no es un gran obstáculo.
No responde a todas sus preguntas, pero en resumen, si tiene muchos datos para buscar y desea un gran rendimiento, entonces Creo que Lucene es definitivamente el camino a seguir. Si usted no va a tener que muchos datos para buscar, entonces usted también podría ir para una base de datos de búsqueda de texto completo. Configurar una búsqueda de texto completo en MySQL es definitivamente más fácil en mi libro.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/ajaxhispano.com/template/agent.layouts/content.php on line 61
2009-04-29 18:23:36
Me sorprende que no haya más información publicada sobre Solr. Solr es bastante similar a Sphinx pero tiene características más avanzadas (AFAIK ya que no he utilizado Sphinx only solo leer sobre él).
La respuesta en el siguiente enlace detalla algunas cosas sobre Sphinx que también se aplica a Solr. Comparación del motor de búsqueda de texto completo-Lucene, Sphinx, Postgresql, MySQL?
Solr también proporciona las siguientes características adicionales:
- Soporta replicación
- Múltiples núcleos (piense en estos como bases de datos separadas con su propia configuración y sus propios índices)
- Búsquedas booleanas
- Resaltado de palabras clave (bastante fácil de hacer en el código de la aplicación si tiene regex-fu; sin embargo, ¿por qué no dejar que una herramienta especializada haga un mejor trabajo para usted)
- Actualizar el índice a través de XML o archivo delimitado
- Comunicarse con el servidor de búsqueda a través de HTTP (incluso puede devolver Json, PHP/Ruby/Python nativo)
- PDF, documento de Word indexación
- Campos dinámicos
- Facetas
- Campos agregados
- Detener palabras, sinónimos, etc.
- Más como esto...
- Indexar directamente desde la base de datos con consultas personalizadas
- Auto-sugerir
- Calentamiento automático de caché
- Indexación rápida (compare con los tiempos de indexación de búsqueda de texto completo de MySQL) Luc Lucene utiliza un formato de índice binario invertido.
- Boosting (reglas personalizadas para aumentar la relevancia de una palabra clave o frase en particular, sucesivamente.)
- Búsquedas en terreno (si un usuario de búsqueda conoce el campo que desea buscar, reduce su búsqueda escribiendo el campo, luego el valor, y SOLO se busca ese campo en lugar de todo much mucho mejor experiencia del usuario)
Por cierto, hay muchas más características; sin embargo, he enumerado solo las características que he utilizado en la producción. POR cierto, fuera de la caja, MySQL soporta #1, #3, y #11 (limitado) en la lista anterior. Para las características que está buscando, una base de datos relacional no va a ser suficiente. Los eliminaría de inmediato.
Además, otro beneficio es que Solr (bueno, Lucene en realidad) es una base de datos de documentos (por ejemplo, NoSQL), por lo que muchos de los beneficios de cualquier otra base de datos de documentos se pueden realizar con Solr. En otras palabras, puede usarlo para algo más que solo buscar (es decir, Rendimiento). Sea creativo con él:)
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/ajaxhispano.com/template/agent.layouts/content.php on line 61
2017-05-23 12:26:17
Apache Solr
Aparte de responder a las consultas de OP, permítanme arrojar algunas ideas sobre Apache Solr de introducción simplea instalación detalladay implementación.
Introducción simple
Cualquier persona que haya tenido experiencia con los motores de búsqueda anteriores, u otros motores no en la lista would me encantaría escuchar su opinion.
Solr no debe usarse para resolver problemas en tiempo real. Para los motores de búsqueda, Solr es prácticamente un juego y funciona perfectamente.
Solr funciona bien en aplicaciones web de Alto Tráfico ( Leí en alguna parte que no es adecuado para esto, pero estoy respaldando esa declaración). Utiliza la RAM, no la CPU.
- relevancia y clasificación de los resultados
El boost te ayuda a clasificar tus resultados en la parte superior. Digamos que estás intentando buscar un nombre john en los campos firstname y lastname , y quieres dar relevancia al campo firstname , entonces necesitas aumentar el campo firstname como se muestra.
http://localhost:8983/solr/collection1/select?q=firstname:john^2&lastname:john
Como se puede ver, firstname campo es aumentado con una puntuación de 2.
Más sobre SolrRelevancy
- velocidad de búsqueda e indexación
La velocidad es increíblemente rápida y no hay compromiso en eso. La razón por la que me mudé a Solr .
En cuanto a la velocidad de indexación, Solr también puede manejar JOINS desde las tablas de su base de datos. Una UNIÓN mayor y compleja afecta la velocidad de indexación. Sin embargo, una enorme configuración de RAM puede abordar fácilmente esta situación.
El mayor es la RAM, más rápida es la velocidad de indexación de Solr.
- facilidad de uso y facilidad de integración con Django
Nunca intentó integrar Solr y Django, sin embargo, puede lograr hacerlo con Haystack. Encontré un interesante artículo sobre el mismo y aquí está el github para ello.
- requisitos de recursos-el sitio se alojará en un VPS, por lo que idealmente motor de búsqueda no requeriría una gran cantidad de RAM y CPU
Solr se reproduce en CARNERO, por lo que si el CARNERO es alto, no tiene que preocuparse por Solr.
El uso de RAM de Solr se dispara en la indexación completa si tiene algunos mil millones de registros, podría usar inteligentemente las importaciones de Delta para hacer frente a esta situación. Como se explicó, Solr es solo una solución casi en tiempo real .
- escalabilidad
Solr es altamente escalable. Echa un vistazo a SolrCloud . Algunas características clave de la misma.
- Shards (o sharding es el concepto de distribuir el índice entre varias máquinas, por ejemplo, si su índice ha crecido demasiado grande)
- Equilibrio de carga (si Solrj se utiliza con Solr cloud, se encarga automáticamente del equilibrio de carga utilizando su mecanismo Round-Robin)
- Búsqueda distribuida
- Alta Disponibilidad
- características adicionales como " did you mean?", búsquedas relacionadas, etc
Para el escenario anterior, podría usar el SpellCheckComponent que está empaquetado con Solr. Hay muchas otras características, La SnowballPorterFilterFactory ayuda a recuperar registros decir que si escribió, books en lugar de book , se le presentarán resultados relacionados con libro.
Esta respuesta se centra ampliamente en Apache Solr & MySQL. Django está fuera de alcance.
Asumiendo que se encuentra en un entorno LINUX, podría continuar con este artículo. (la mía era una versión de Ubuntu 14.04)
Instalación detallada
Primeros pasos
Descarga Apache Solrdesde aquí. Que sería la versión es 4.8.1. Usted podría descargar nuevo versiones, encontré este estable.
Después de descargar el archivo , extráigalo a una carpeta de su elección.
Decir .. Downloads o lo que sea.. Así que se verá como Downloads/solr-4.8.1/
En su solicitud.. Navegar dentro del directorio
shankar@shankar-lenovo: cd Downloads/solr-4.8.1
Así que ahora estás aquí ..
shankar@shankar-lenovo: ~/Downloads/solr-4.8.1$
Inicie el Servidor de aplicaciones Jetty
Jetty está disponible dentro de la carpeta examples del directorio solr-4.8.1, así que navegue dentro de eso e inicie Servidor de Aplicaciones Jetty.
shankar@shankar-lenovo:~/Downloads/solr-4.8.1/example$ java -jar start.jar
Ahora , no cierre el terminal , minimícelo y déjelo a un lado.
(CONSEJO : Usar & después del inicio.jar para hacer que el servidor Jetty se ejecute en el antecedentes)
Para comprobar si Apache Solr se ejecuta correctamente, visite esta URL en el navegador. http://localhost:8983/solr
Ejecución de embarcadero en puerto personalizado
Se ejecuta en el puerto 8983 por defecto. Podrías cambiar el puerto ya sea aquí o directamente dentro del archivo jetty.xml.
java -Djetty.port=9091 -jar start.jar
Descargar el JConnector
Este archivo JAR actúa como un puente entre MySQL y JDBC , Descargue la Versión Independiente de la Plataforma aquí
Después de descargarlo, extraiga la carpeta y copie elmysql-connector-java-5.1.31-bin.jar y péguelo en el directorio lib.
shankar@shankar-lenovo:~/Downloads/solr-4.8.1/contrib/dataimporthandler/lib
Creando la tabla MySQL para ser enlazada a Apache Solr
Para poner Solr a use, Necesita tener algunas tablas y datos para buscar. Para eso, usaremos MySQL para crear una tabla y empujar algunos nombres aleatorios y luego podríamos usar Solr para conectarnos a MySQL e indexar esa tabla y sus entradas.
1.Estructura de la tabla
CREATE TABLE test_solr_mysql
(
id INT UNSIGNED NOT NULL AUTO_INCREMENT,
name VARCHAR(45) NULL,
created TIMESTAMP NULL DEFAULT CURRENT_TIMESTAMP,
PRIMARY KEY (id)
);
2.Rellene el cuadro anterior
INSERT INTO `test_solr_mysql` (`name`) VALUES ('Jean');
INSERT INTO `test_solr_mysql` (`name`) VALUES ('Jack');
INSERT INTO `test_solr_mysql` (`name`) VALUES ('Jason');
INSERT INTO `test_solr_mysql` (`name`) VALUES ('Vego');
INSERT INTO `test_solr_mysql` (`name`) VALUES ('Grunt');
INSERT INTO `test_solr_mysql` (`name`) VALUES ('Jasper');
INSERT INTO `test_solr_mysql` (`name`) VALUES ('Fred');
INSERT INTO `test_solr_mysql` (`name`) VALUES ('Jenna');
INSERT INTO `test_solr_mysql` (`name`) VALUES ('Rebecca');
INSERT INTO `test_solr_mysql` (`name`) VALUES ('Roland');
Entrando en el núcleo y añadiendo las directivas lib
1.Navegar a
shankar@shankar-lenovo: ~/Downloads/solr-4.8.1/example/solr/collection1/conf
2.Modificando el solrconfig.xml
Agregue estas dos directivas a este archivo..
<lib dir="../../../contrib/dataimporthandler/lib/" regex=".*\.jar" />
<lib dir="../../../dist/" regex="solr-dataimporthandler-\d.*\.jar" />
Ahora agregue el DIH (Controlador de importación de datos)
<requestHandler name="/dataimport"
class="org.apache.solr.handler.dataimport.DataImportHandler" >
<lst name="defaults">
<str name="config">db-data-config.xml</str>
</lst>
</requestHandler>
3.Cree el db-data-config.archivo xml
Si el archivo existe entonces ignore, agregue estas líneas a ese archivo. Como puede ver en la primera línea, debe proporcionar las credenciales de su base de datos MySQL. El nombre de la base de datos, nombre de usuario y contraseña.
<dataConfig>
<dataSource type="JdbcDataSource" driver="com.mysql.jdbc.Driver" url="jdbc:mysql://localhost/yourdbname" user="dbuser" password="dbpass"/>
<document>
<entity name="test_solr" query="select CONCAT('test_solr-',id) as rid,name from test_solr_mysql WHERE '${dataimporter.request.clean}' != 'false'
OR `created` > '${dataimporter.last_index_time}'" >
<field name="id" column="rid" />
<field name="solr_name" column="name" />
</entity>
</document>
</dataConfig>
(CONSEJO: Puede tener cualquier número de entidades, pero cuidado con el campo id, si son iguales entonces la indexación se saltará. )
4.Modificar el esquema.archivo xml
Añada esto a su esquema .xml como se muestra..
<uniqueKey>id</uniqueKey>
<field name="solr_name" type="string" indexed="true" stored="true" />
Aplicación
Indexación
Aquí es donde está el verdadero negocio. Necesita hacer la indexación de datos de MySQL a Solr para hacer uso de consultas Solr.
Paso 1: Ir al Panel de Administración de Solr
Pulsa la URL http://localhost:8983/solr en su navegador. La pantalla se abre así.
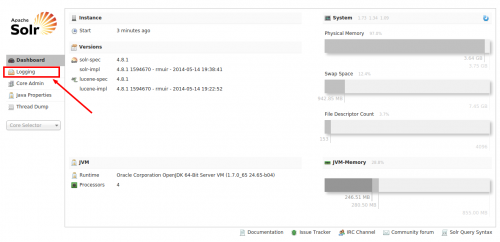
Como indica el marcador, vaya a Logging inorder para verificar si alguna de las configuraciones anteriores ha dado lugar a errores.
Paso 2: Revisa tus registros
Ok así que ahora estás aquí, como puedes, hay muchos mensajes amarillos (ADVERTENCIAS). Asegúrese de que no tiene mensajes de error marcados en rojo. Anteriormente, en nuestra configuración habíamos añadido una consulta select en nuestro db-data-config.xml , digamos que si hubiera algún error en esa consulta, se habría mostrado aquí.
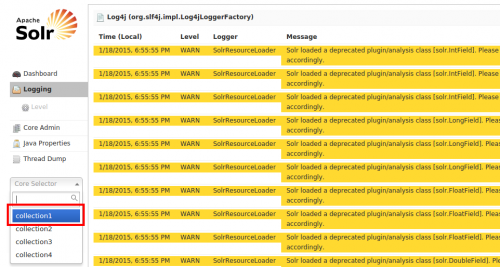
Bien, sin errores. Estamos listos para irnos. Vamos a elegir collection1 de la lista como se representa y seleccione Dataimport
Paso 3: DIH (Controlador de Importación de datos)
Usando el DIH, se conectará a MySQLdesde Solra través del archivo de configuración db-data-config.xml de la Solr interfaz y recuperar los 10 registros de la base de datos que se indica en Solr.
Para hacer eso, Elija full-import, y marque las opciones Clean y Commit. Ahora haga clic en Ejecutar como se muestra.
Alternativamente, puede usar una consulta directa de importación completa como esta también..
http://localhost:8983/solr/collection1/dataimport?command=full-import&commit=true
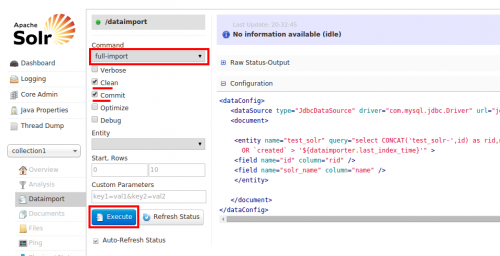
Después de hacer clic Ejecutar, Solr comienza a indexar el registros, si hubiera algún error, diría Indexación Falliday usted tiene que volver a la sección Registro para ver lo que ha salido mal.
Suponiendo que no hay errores con esta configuración y si la indexación se completa con éxito., usted recibiría esta notificación.

Paso 4: Ejecutar Consultas Solr
Parece que todo salió bien, ahora podría usar Consultas Solr para consultar los datos que se indexaron. Haga clic en el Query a la izquierda y luego presione el botón Execute en la parte inferior.
Verá los registros indexados como se muestra.
La correspondiente Solr consulta para listar todos los registros es
http://localhost:8983/solr/collection1/select?q=*:*&wt=json&indent=true

Bueno, ahí van los 10 registros indexados. Digamos que solo necesitamos nombres que comiencen con Ja , en este caso, debe apuntar al nombre de la columna solr_name, por lo tanto, su consulta es como este.
http://localhost:8983/solr/collection1/select?q=solr_name:Ja*&wt=json&indent=true

Así es como escribes Consultas Solr. Para leer más al respecto, Consulte este hermoso artículo .
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/ajaxhispano.com/template/agent.layouts/content.php on line 61
2015-01-19 11:51:34
Estoy viendo la búsqueda de texto completo de PostgreSQL en este momento, y tiene todas las características correctas de un motor de búsqueda moderno, muy buen carácter extendido y soporte multilingüe, buena integración estrecha con los campos de texto en la base de datos.
Pero no tiene operadores de búsqueda fáciles de usar como + or AND (usa &/!) y no estoy encantado con cómo funciona en su sitio de documentación. Si bien tiene negrita de términos de coincidencia en los fragmentos de resultados, el algoritmo predeterminado para el que coincide términos no es genial. Además, si desea indexar rtf, PDF, MS Office, debe encontrar e integrar un convertidor de formato de archivo.
OTOH, es mucho mejor que la búsqueda de texto MySQL, que ni siquiera indexa palabras de tres letras o menos. Es el valor predeterminado para la búsqueda de MediaWiki, y realmente creo que no es bueno para los usuarios finales: http://www.searchtools.com/analysis/mediawiki-search /
En todos los casos que he visto, Lucene / Solr y Sphinx son realmente grandes. Son código sólido y han evolucionado con mejoras significativas en la usabilidad, por lo que las herramientas están ahí para hacer búsquedas que satisfagan a casi todos.
Para SHAILI - SOLR incluye la biblioteca de código de búsqueda de Lucene y tiene los componentes para ser un buen motor de búsqueda independiente.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/ajaxhispano.com/template/agent.layouts/content.php on line 61
2009-09-17 22:57:50
Solo mis dos centavos a esta vieja pregunta. Recomiendo encarecidamente echar un vistazo a ElasticSearch .
Elasticsearch es un servidor de búsqueda basado en Lucene. Proporciona un motor de búsqueda de texto completo distribuido con capacidad multitenant con una interfaz web RESTful y documentos JSON sin esquema. Elasticsearch está desarrollado en Java y se publica como código abierto bajo los términos de la Licencia Apache.
Las ventajas sobre otros FTS (búsqueda de texto completo) Los motores son:
- Interfaz RESTful
- Mejor escalabilidad
- Gran comunidad
- Construido por Lucene desarrolladores
- Amplia documentación
- Hay muchas bibliotecas de código abierto disponibles (incluyendo Django)
Estamos usando este motor de búsqueda en nuestro proyecto y muy contentos con él.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/ajaxhispano.com/template/agent.layouts/content.php on line 61
2014-01-21 19:07:12
SearchTools-Avi dijo "Búsqueda de texto MySQL, que ni siquiera indexa palabras de tres letras o menos."
FYIs, la longitud mínima de palabra de MySQL fulltext es ajustable desde al menos MySQL 5.0. Google 'mysql fulltext min length' para instrucciones simples.
Dicho esto, MySQL fulltext tiene limitaciones: por un lado, se vuelve lento para actualizar una vez que se llega a un millón de registros o así,...
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/ajaxhispano.com/template/agent.layouts/content.php on line 61
2009-09-28 00:51:39
Añadiría mnoGoSearch a la lista. Solución extremadamente eficiente y flexible, que funciona como Google: indexer obtiene datos de múltiples sitios, puede usar criterios básicos o inventar Sus propios ganchos para tener la máxima calidad de búsqueda. También podría obtener los datos directamente de la base de datos.
La solución no es tan conocida hoy en día, pero satisface las necesidades máximas. Puede compilarlo e instalarlo o en un servidor independiente, o incluso en su servidor principal, no es necesario muchos recursos como Solr, ya que está escrito en C y funciona perfectamente incluso en servidores pequeños.
Al principio necesita compilarlo Usted Mismo, por lo que requiere algo de conocimiento. Hice un pequeño script para Debian, que podría ayudar. Cualquier ajuste es bienvenido.
Como está utilizando Django framework, podría usar o cliente PHP en el medio, o encontrar una solución en Python, vi algunos artículos .
Y, por supuesto, mnoGoSearch es de código abierto, GNU GPL.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/ajaxhispano.com/template/agent.layouts/content.php on line 61
2013-06-20 21:06:18