Propósito de la alineación de memoria
Es cierto que no lo entiendo. Digamos que tienes una memoria con una palabra de memoria de longitud de 1 byte. ¿Por qué no puede acceder a una variable larga de 4 bytes en un acceso de memoria única en una dirección no alineada(es decir, no divisible por 4), como es el caso con direcciones alineadas?
8 answers
Es una limitación de muchos procesadores subyacentes. Por lo general, se puede trabajar haciendo 4 búsquedas ineficientes de un solo byte en lugar de una búsqueda eficiente de palabras, pero muchos especificadores de lenguaje decidieron que sería más fácil prohibirlas y forzar que todo esté alineado.
Hay mucha más información en este enlace que el OP descubierto.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/ajaxhispano.com/template/agent.layouts/content.php on line 61
2008-12-19 17:39:22
El subsistema de memoria en un procesador moderno está restringido a acceder a la memoria en la granularidad y la alineación de su tamaño de palabra; este es el caso por una serie de razones.
Velocidad
Los procesadores modernos tienen múltiples niveles de memoria caché a través de los cuales se deben extraer los datos; soportar lecturas de un solo byte haría que el rendimiento del subsistema de memoria esté estrechamente vinculado al rendimiento de la unidad de ejecución (también conocido como cpu-bound); todo esto recuerda cómo el modo PIO fue superado por DMA por muchas de las mismas razones en discos duros.
La CPU siempre lee en su tamaño de palabra (4 bytes en un procesador de 32 bits), por lo que cuando se hace un acceso de dirección sin alineación-en un procesador que lo soporta - el procesador va a leer varias palabras. La CPU leerá cada palabra de memoria que su dirección solicitada se encuentre a caballo. Esto provoca una amplificación de hasta 2 VECES el número de transacciones de memoria necesarias para acceder a los datos solicitados.
Debido a esto, se puede ser muy fácilmente más lento para leer dos bytes que cuatro. Por ejemplo, supongamos que tiene una estructura en la memoria que se ve así:
struct mystruct {
char c; // one byte
int i; // four bytes
short s; // two bytes
}
En un procesador de 32 bits lo más probable es que esté alineado como se muestra aquí:
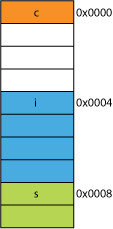
El procesador puede leer cada uno de estos miembros en una transacción.
Digamos que tiene una versión empaquetada de la estructura, tal vez de la red donde se empaquetó para la eficiencia de transmisión; podría parecer algo como esto:
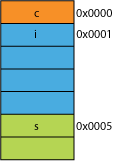
Leer el primer byte va a ser lo mismo.
Cuando le pides al procesador que te dé 16 bits de 0x0005, tendrá que leer una palabra de 0x0004 y desplazar a la izquierda 1 byte para colocarla en un registro de 16 bits; algo de trabajo extra, pero la mayoría puede manejar eso en un ciclo.
Cuando pides 32 bits de 0x0001 obtendrás una amplificación de 2X. El procesador leerá desde 0x0000 en el registro de resultados y desplazará a la izquierda 1 byte, luego volverá a leer desde 0x0004 en un registro temporal, cambie a la derecha 3 bytes, luego OR con el registro de resultados.
Rango
Para cualquier espacio de direcciones dado, si la arquitectura puede asumir que los 2 LSBs son siempre 0 (por ejemplo, máquinas de 32 bits), entonces puede acceder a 4 veces más memoria (los 2 bits guardados pueden representar 4 estados distintos), o la misma cantidad de memoria con 2 bits para algo como flags. Tomar los 2 LSBs de una dirección le daría una alineación de 4 bytes; también conocido como zancada de 4 bytes. Cada vez que se incrementa una dirección se incrementa efectivamente el bit 2, no el bit 0, es decir, los últimos 2 bits siempre seguirán siendo 00.
Esto puede incluso afectar el diseño físico del sistema. Si el bus de direcciones necesita 2 bits menos, puede haber 2 pines menos en la CPU y 2 rastros menos en la placa de circuito.
Atomicidad
La CPU puede operar en una palabra alineada de memoria atómicamente, lo que significa que ninguna otra instrucción puede interrumpir esa operación. Esto es crítico para el correcto funcionamiento de muchos estructuras de datos libres de bloqueo y otros paradigmas de concurrencia.
Conclusión
El sistema de memoria de un procesador es bastante más complejo e involucrado de lo que se describe aquí; una discusión sobre cómo un procesador x86 realmente aborda la memoria puede ayudar (muchos procesadores funcionan de manera similar).
Hay muchos más beneficios de adherirse a la alineación de memoria que puede leer en esto IBM article.
El uso principal de una computadora es transformar datos. Las arquitecturas y tecnologías de memoria modernas se han optimizado durante décadas para facilitar la obtención de más datos, entrada, salida y entre más y más unidades de ejecución, de una manera altamente confiable.
Bonus: Cachés
Otra alineación para el rendimiento a la que aludí anteriormente es la alineación en líneas de caché que son (por ejemplo, en algunas CPU) 64B.
Para obtener más información sobre cuánto rendimiento se puede obtener al aprovechar las cachés, eche un vistazo a Galería de Efectos de Caché de Procesador ; de esta pregunta sobre tamaños de línea de caché
La comprensión de las líneas de caché puede ser importante para ciertos tipos de optimizaciones de programas. Por ejemplo, la alineación de datos puede determinar si una operación toca una o dos líneas de caché. Como vimos en el ejemplo anterior, esto puede significar fácilmente que en el caso desalineado, la operación será dos veces más lenta.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/ajaxhispano.com/template/agent.layouts/content.php on line 61
2017-10-21 00:52:02
Se puede con algunos procesadores ( el nehalem puede hacer esto), pero anteriormente todo el acceso a la memoria estaba alineado en una línea de 64 bits (o 32 bits), debido a que el bus tiene 64 bits de ancho, tenía que obtener 64 bits a la vez, y era significativamente más fácil obtener estos en 'trozos' alineados de 64 bits.
Entonces, si querías obtener un solo byte, buscabas el fragmento de 64 bits y luego enmascarabas los bits que no querías. Fácil y rápido si su byte estaba en el extremo derecho, pero si estaba en el medio de ese trozo de 64 bits, tendría que enmascarar los bits no deseados y luego cambiar los datos al lugar correcto. Peor aún, si quería una variable de 2 bytes, pero que se dividió en 2 trozos, entonces que requiere el doble de los accesos de memoria necesarios.
Así que, como todo el mundo piensa que la memoria es barata, simplemente hicieron que el compilador alineara los datos en los tamaños de fragmentos del procesador para que su código se ejecute más rápido y de manera más eficiente a costa de la memoria desperdiciada.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/ajaxhispano.com/template/agent.layouts/content.php on line 61
2008-12-19 15:31:47
Fundamentalmente, la razón es porque el bus de memoria tiene una longitud específica que es mucho, mucho más pequeña que el tamaño de la memoria.
Por lo tanto, la CPU lee fuera de la caché L1 en el chip, que a menudo es de 32 KB en estos días. Pero el bus de memoria que conecta la caché L1 a la CPU tendrá el ancho mucho más pequeño del tamaño de la línea de caché. Esto será del orden de 128 bits.
Así que:
262,144 bits - size of memory
128 bits - size of bus
Los accesos desalineados ocasionalmente solaparán dos líneas de caché, y esto requiere una lectura de caché completamente nueva para obtener los datos. Incluso podría perderse todo el camino hasta el DRAM.
Además, alguna parte de la CPU tendrá que pararse sobre su cabeza para armar un solo objeto de estas dos líneas de caché diferentes que cada una tiene una pieza de los datos. En una línea, estará en los bits de orden muy alto, en el otro, los bits de orden muy bajo.
Habrá hardware dedicado completamente integrado en la tubería que maneja el movimiento alineado objetos en los bits necesarios del bus de datos de la CPU, pero tal hardware puede carecer para objetos desalineados, porque probablemente tiene más sentido usar esos transistores para acelerar programas optimizados correctamente.
En cualquier caso, la segunda lectura de memoria que a veces es necesaria ralentizaría la canalización sin importar cuánto hardware de propósito especial se dedicara (hipotética y tontamente) a parchear operaciones de memoria desalineadas.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/ajaxhispano.com/template/agent.layouts/content.php on line 61
2011-03-01 18:38:58
@joshperry ha dado una excelente respuesta a esta pregunta. Además de su respuesta, tengo algunos números que muestran gráficamente los efectos que se describieron, especialmente la amplificación 2X. Aquí hay un enlace a una hoja de cálculo de Google que muestra el efecto de diferentes alineaciones de palabras. Además aquí hay un enlace a un Github gist con el código para la prueba. El código de prueba está adaptado de el artículo escrito por Jonathan Rentzsch que @joshperry referenciado. Las pruebas se realizaron en un Macbook Pro con un procesador Intel Core i7 de 64 bits de 2,8 GHz de cuatro núcleos y 16 GB de RAM.

Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/ajaxhispano.com/template/agent.layouts/content.php on line 61
2016-04-06 14:38:53
Si un sistema con memoria direccionable a bytes tiene un bus de memoria de 32 bits de ancho, eso significa que hay efectivamente cuatro sistemas de memoria de ancho de bytes que están cableados para leer o escribir la misma dirección. Una lectura alineada de 32 bits requerirá información almacenada en la misma dirección en los cuatro sistemas de memoria, por lo que todos los sistemas pueden suministrar datos simultáneamente. Una lectura no alineada de 32 bits requeriría algunos sistemas de memoria para devolver datos de una dirección, y algunos para devolver datos de la siguiente dirección superior. Aunque hay algunos sistemas de memoria que están optimizados para poder cumplir con tales solicitudes (además de su dirección, tienen efectivamente una señal "más uno" que les hace usar una dirección más alta de lo especificado) tal característica agrega un costo considerable y complejidad a un sistema de memoria; la mayoría de los sistemas de memoria básicos simplemente no pueden devolver porciones de diferentes palabras de 32 bits al mismo tiempo.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/ajaxhispano.com/template/agent.layouts/content.php on line 61
2011-06-15 20:21:36
Si tiene un bus de datos de 32 bits, las líneas de dirección del bus de direcciones conectadas a la memoria comenzarán desde un2, por lo tanto, solo se puede acceder a direcciones alineadas de 32 bits en un solo ciclo de bus.
Entonces, si una palabra abarca un límite de alineación de direcciones, es decir, un0 para datos de 16/32 bits o A1 para los datos de 32 bits no son cero, se requieren dos ciclos de bus para obtener los datos.
Algunas arquitecturas / conjuntos de instrucciones no admiten el acceso no alineado y generarán una excepción en tales intentos, el código de acceso no alineado generado por el compilador requiere no solo ciclos de bus adicionales, sino instrucciones adicionales, lo que lo hace aún menos eficiente.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/ajaxhispano.com/template/agent.layouts/content.php on line 61
2014-06-19 20:10:06
En PowerPC puede cargar un entero desde una dirección impar sin problemas.
Sparc e I86 y (creo) Itatnium levantan excepciones de hardware cuando intentas esto.
Una carga de 32 bits vs cuatro cargas de 8 bits no va a hacer mucha diferencia en la mayoría de los procesadores modernos. Si los datos ya están en caché o no tendrá un efecto mucho mayor.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/ajaxhispano.com/template/agent.layouts/content.php on line 61
2014-06-19 19:53:05