¿Por qué escalar funciones?
Descubrí que los problemas de escalado en SVM (Support Vector Machine) realmente mejoran su rendimiento... He leído esta explicación:
"La principal ventaja de escalar es evitar que los atributos en rangos numéricos mayores dominen a aquellos en rangos numéricos más pequeños."
Desafortunadamente esto no me ayudó ... ¿Puede alguien darme una mejor explicación? Gracias de antemano!
7 answers
La verdadera razón detrás de las características de escalado en SVM es el hecho de que este clasificador no es invariante de transformación afín. En otras palabras, si multiplica una característica por un 1000 que una solución dada por SVM será completamente diferente. No tiene casi nada que ver con las técnicas de optimización subyacentes (aunque se ven afectados por estos problemas de escalas, todavía deben converger a óptimo global).
Consideremos un ejemplo: tenemos al hombre y a la mujer, codificados por su sexo y altura (dos características). Supongamos un caso muy simple con tales datos:
0-hombre, 1 mujer-
1 150
1 160
1 170
0 180
0 190
0 200
Y hagamos algo tonto. Entrénalo para predecir el sexo de la persona, por lo que estamos tratando de aprender f(x,y)=x (ignorando el segundo parámetro).
Es fácil ver, que para tales datos el clasificador de margen más grande "cortará" el plano horizontalmente en algún lugar alrededor de la altura "175", así que una vez que obtenemos la nueva muestra "0 178" (una mujer de 178cm de altura) obtenemos la clasificación de que ella es un hombre.
Sin embargo, si reducimos todo a [0,1] obtenemos sth como
0 0.0
0 0.2
0 0.4
1 0.6
1 0.8
1 1.0
Y ahora el clasificador de margen más grande "corta" el plano casi verticalmente (como se esperaba) y así dada la nueva muestra "0 178" que también se escala a alrededor de "0 0.56" obtenemos que es una mujer (¡correcto!)
So en general, el escalado asegura que solo porque algunas características son grandes no conducirá a usarlas como un predictor principal .
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/ajaxhispano.com/template/agent.layouts/content.php on line 61
2018-02-24 20:21:39
El escalado de características es un truco general aplicado a problemas de optimización (no solo SVM). El algoritmo de subrayado para resolver el problema de optimización de SVM es gradient descend. Andrew Ng tiene una gran explicación en sus videos de coursera aquí.
Ilustraré las ideas centrales aquí (tomo prestadas las diapositivas de Andrew). Supongamos que solo tiene dos parámetros y uno de los parámetros puede tomar un rango relativamente grande de valores. Entonces el contorno de la función de costo
puede parecer muy alto y óvalos delgados (ver óvalos azules abajo). Sus gradientes (la trayectoria del gradiente se dibuja en rojo) podrían tomar mucho tiempo y ir y venir para encontrar la solución óptima.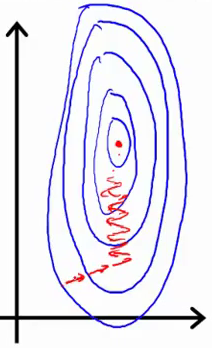
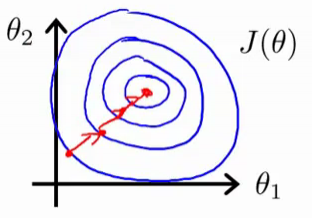
En cambio, si ha escalado su entidad, el contorno de la función de costo podría parecer círculos; entonces el gradiente puede tomar un camino mucho más recto y lograr el punto óptimo mucho más rápido.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/ajaxhispano.com/template/agent.layouts/content.php on line 61
2014-10-07 06:02:22
Solo pensamientos personales desde otra perspectiva.
1. ¿por qué la influencia del escalado de características?
Hay una palabra en la aplicación del algoritmo de aprendizaje automático, 'basura adentro, basura afuera'. Cuanto más real sea el reflejo de sus características, más precisión obtendrá su algoritmo. Esto también se aplica a la forma en que los algoritmos de aprendizaje automático tratan la relación entre las características. A diferencia del cerebro humano, cuando los algoritmos de aprendizaje automático hacen la clasificación, por ejemplo, todas las características se expresan y calculado por el mismo sistema de coordenadas, que en cierto sentido, establece una suposición a priori entre las características(no realmente reflejo de los datos en sí). Y también la naturaleza de la mayoría de los algoritmos es encontrar el porcentaje de peso más apropiado entre las características para ajustar los datos. Entonces, cuando la entrada de estos algoritmos es características sin escala, los datos a gran escala tienen más influencia en el peso. En realidad no es el reflejo de los datos en sí mismo.
2. por qué normalmente característica ¿el escalado mejora la precisión?
La práctica común en los algoritmos de aprendizaje automático no supervisados sobre la selección de hiper-parámetros(o hiper-hiper parámetros) (por ejemplo, el proceso hierachical Dirichlet, hLDA) es que no debe agregar ninguna suposición subjetiva personal sobre los datos. La mejor manera es asumir que tienen la probabilidad de igualdad para aparecer. Creo que se aplica aquí también. El escalado de características solo intente hacer la suposición de que todas las características tienen la igualdad oportunidad de influir en el peso, que más realmente refleja la información / conocimiento que usted sabe sobre los datos. Comúnmente también resultan en una mejor precisión.
Por cierto, sobre la invariante de transformación afín y convergen más rápido, hay un enlace de interés aquí en stats.stackexchange.com.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/ajaxhispano.com/template/agent.layouts/content.php on line 61
2017-04-13 12:44:17
De lo que he aprendido del curso de Andrew Ng en coursera es que el escalado de características nos ayuda a lograr el gradiente decente más rápidamente,si los datos están más dispersos, eso significa que si tiene una desviación de standerd más alta, tomará relativamente más tiempo calcular el gradiente decente en comparación con la situación cuando escalamos nuestros datos a través del escalado de características
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/ajaxhispano.com/template/agent.layouts/content.php on line 61
2017-04-18 13:35:32
Podemos acelerar el descenso del gradiente teniendo cada uno de nuestros valores de entrada en aproximadamente el mismo rango. Esto se debe a que θ descenderá rápidamente en rangos pequeños y lentamente en rangos grandes, y así oscilará ineficientemente hasta el óptimo cuando las variables son muy desiguales. Esto es del curso Andrews NG Coursera.
Por lo tanto, se hace para hacer algo como estandarizar los datos. A veces los investigadores quieren saber si una observación específica es común o excepcional. expresar una puntuación en términos del número de desviaciones estándar se elimina de la media. Este número es lo que llamamos una puntuación z. Si recodificamos las puntuaciones originales en z-scores, decimos que estandarizamos una variable.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/ajaxhispano.com/template/agent.layouts/content.php on line 61
2017-08-15 03:05:07
La Idea de escalar es eliminar cálculos de exess en una variable particular estandarizando toda la variable en una misma escala con esto tendemos a calcular la pendiente mucho más fácil ( y = mx + c) donde estamos normalizando el parámetro M para converger lo más rápido posible.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/ajaxhispano.com/template/agent.layouts/content.php on line 61
2017-11-11 23:04:18
Sí si la normalización no está allí, contour será delgado, por lo tanto, con la normalización:
- Los valores están dentro del rango
- Acelera el cálculo de theta porque el número de cálculos requeridos será menor
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/ajaxhispano.com/template/agent.layouts/content.php on line 61
2017-12-08 07:23:56